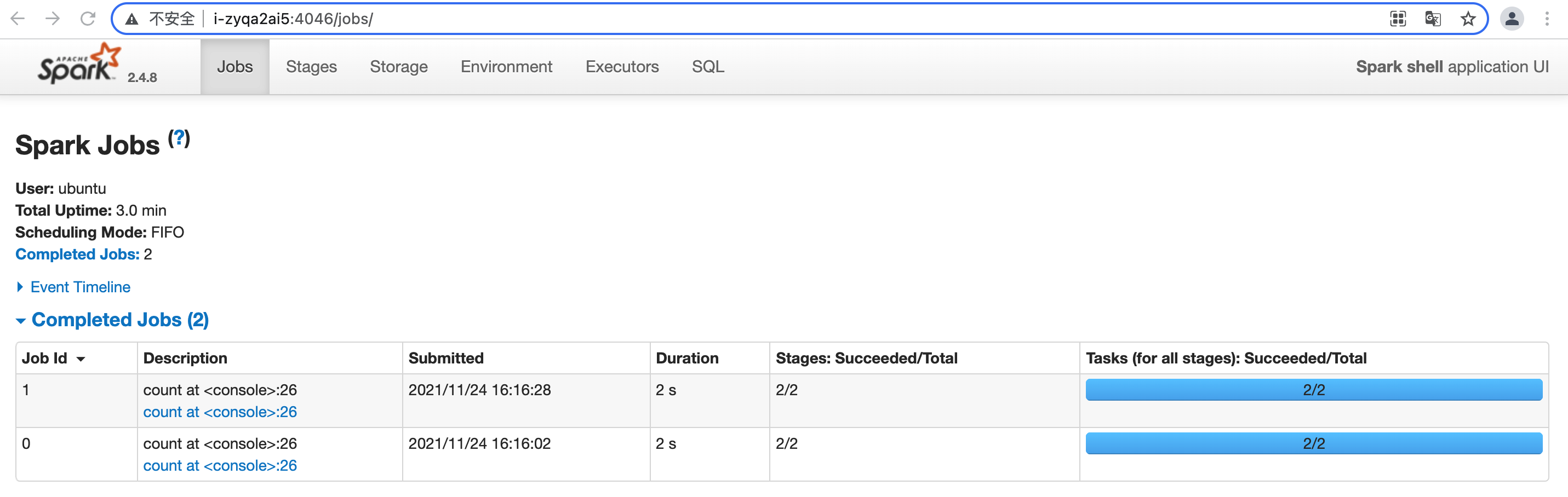
提交 Spark job
QingMR 集群创建成功后,您可以通过 Client 创建并执行 Spark job。
前提条件
-
已获取管理控制台登录账号和密码,且已获取集群操作权限。
-
已创建 QingMR 集群,且集群状态为
活跃。 -
已打通集群网络,使集群云服务器能面向互联网提供服务。例如使用端口转发或 VPN 等方式打通网络,详细操作请参见访问组件 Web 页面。
配置 Spark 模式
您可以选择是否开启 Spark Standalone 模式。
-
开启后您将以 Spark Standalone 模式提交 Spark 应用。
-
关闭后您将以 Spark on YARN 模式提交 Spark 应用(从 1.1.0 开始默认关闭),推荐使用 Spark on YARN 模式。
若仅以 Spark on YARN 模式提交 Spark 应用或者仅使用 Hadoop 相关功能,您可以选择关闭 Spark Standalone 模式以释放资源。
具体操作步骤如下:
-
登录管理控制台。
-
选择产品与服务 > 大数据服务 > 大数据引擎 QingMR,进入集群管理页面。
-
选择目标集群,点击目标集群 ID,进入集群详情页面。
-
选择配置参数页签,点击修改属性。
说明 enable_spark_standalone 参数建议不要和其他配置参数项一起修改,推荐单独修改此项然后保存设置。
-
设置为 Spark on YARN 模式
设置 enable_spark_standalone 参数为false。
-
设置为 Spark Standalone 模式
设置 enable_spark_standalone 参数为true。
-
-
点击保存。
在 Spark on YARN 模式提交 job
Spark on YARN 模式需设置 enable_spark_standalone 为 false,详细操作请参见配置 Spark 模式。
Spark job(shell)
在 Client 节点上执行以下命令:
| 说明 |
|---|
您也可以将测试文件上传到 hdfs,然后将代码中的文件路径替换为 hdfs 上的文件路径,例如 hdfs://user/ubuntu/README.md。 |
-
Scala
cd /opt/spark bin/spark-shell --master yarn val textFile = spark.read.textFile("file:///opt/spark/README.md") textFile.count() textFile.filter(line => line.contains("Spark")).count() -
Python
cd /opt/spark bin/pyspark --master yarn textFile = spark.read.text("file:///opt/spark/README.md") textFile.count() textFile.filter(textFile.value.contains("Spark")).count() -
R
cd /opt/spark bin/sparkR --master yarn df <- as.DataFrame(faithful) head(df) people <- read.df("file:///opt/spark/examples/src/main/resources/people.json", "json") printSchema(people)
Spark job (jar)
在 Client 节点上执行以下命令:
-
Scala
cd /opt/spark bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --num-executors 3 --executor-cores 1 --executor-memory 1g examples/jars/spark-examples_2.12-2.4.8.jar 100
说明 spark-examples_2.12-2.4.8.jar为您集群中对应的 JAR 包名称,您可以在 Client 节点的 opt/spark/examples/jars 路径下获取。 -
Python
cd /opt/spark bin/spark-submit --master yarn --deploy-mode client examples/src/main/python/pi.py 100
-
R
cd /opt/spark bin/spark-submit --master yarn --deploy-mode cluster /opt/spark/examples/src/main/r/ml/kmeans.R
查看作业信息
在 Spark on YARN 模式提交 Spark job 后,在浏览器输入“http://<主节点 IP>:808”,访问 Yarn UI 查看 job 记录。
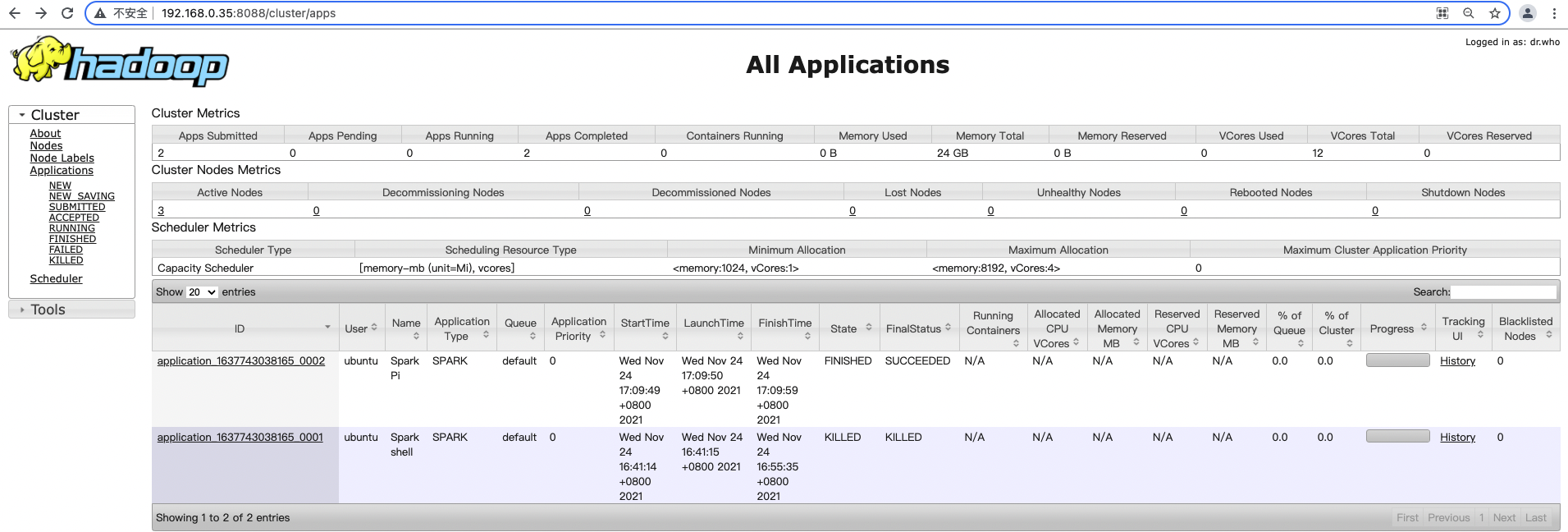
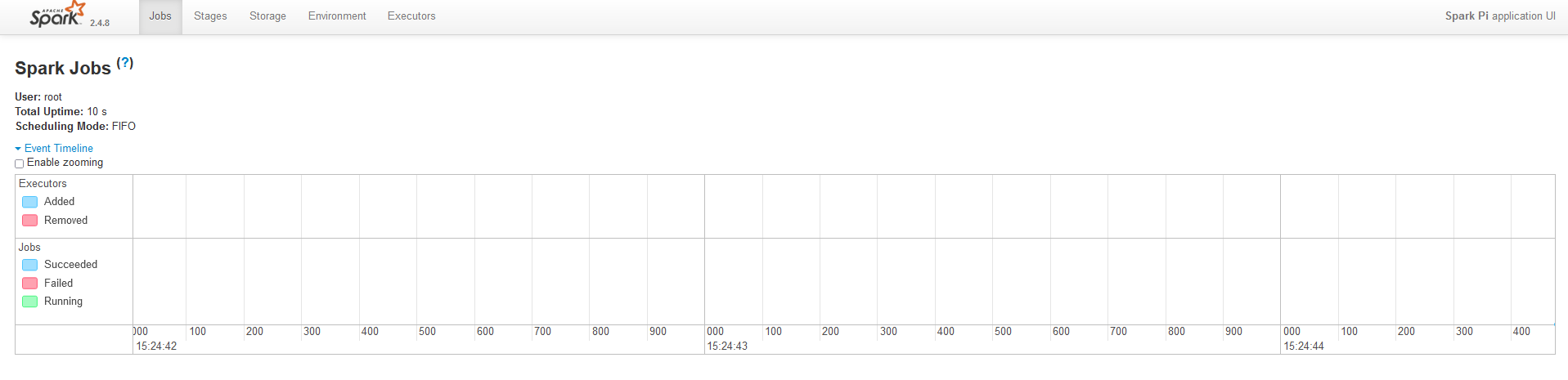
在 job 运行过程中,可以单击任务的 Tracking UI 链接,查看 job 的详细信息。
在 Spark Standalone 模式提交 job
Spark Standalone 模式需要设置 enable_spark_standalone 为 true,详细操作请参见配置 Spark 模式。
Spark job(shell)
在 Client 节点上执行以下命令:
| 说明 |
|---|
您也可以将测试文件上传到 hdfs,然后将代码中的文件路径替换为 hdfs 上的文件路径,例如 hdfs://user/ubuntu/README.md。 |
-
Scala
cd /opt/spark bin/spark-shell --master spark://<主节点 IP>:7077 val textFile = spark.read.textFile("file:///opt/spark/README.md") textFile.count() textFile.filter(line => line.contains("Spark")).count() -
Python
cd /opt/spark bin/pyspark --master spark://<主节点 IP>:7077 textFile = spark.read.text("file:///opt/spark/README.md") textFile.count() textFile.filter(textFile.value.contains("Spark")).count() -
R
cd /opt/spark bin/sparkR --master spark://<主节点 IP>:7077 df <- as.DataFrame(faithful) head(df) people <- read.df("file:///opt/spark/examples/src/main/resources/people.json", "json") printSchema(people)
Spark job(jar)
在 Client 节点上执行以下命令:
-
Scala
cd /opt/spark bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://<主节点 IP>:7077 examples/jars/spark-examples_2.12-2.4.8.jar 100说明 spark-examples_2.12-2.4.8.jar为您集群中对应的JAR包名称,您可以在 Client 节点的 opt/spark/examples/jars 路径下获取。 -
Python
cd /opt/spark bin/spark-submit --master spark://<主节点 IP>:7077 examples/src/main/python/pi.py 100可以在配置参数页面切换 Python 版本。

-
R
cd /opt/spark bin/spark-submit --master spark://<主节点 IP>:7077 examples/src/main/r/data-manipulation.R examples/src/main/resources/people.txt
查看作业信息
在 Spark Standalone 模式提交 Spark job 后,在浏览器输入“http://<主节点 IP>:8080”,访问 Spark UI 查看 job 记录。
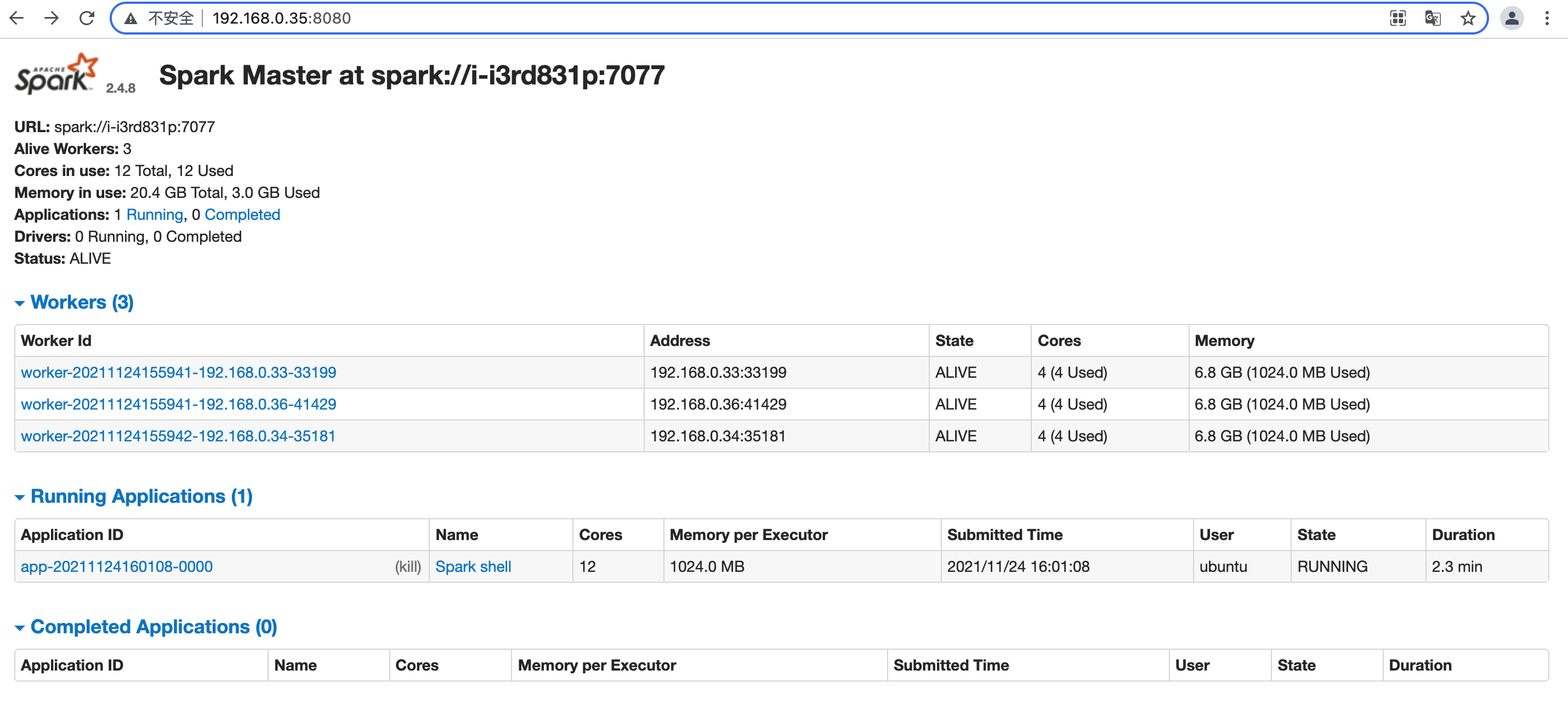
在 job 运行过程中,可以单击 Applocation Name 链接,查看 job 的详细信息。